 缓存雪崩,缓存穿透和缓存击穿
缓存雪崩,缓存穿透和缓存击穿
# 数据不一致的原因
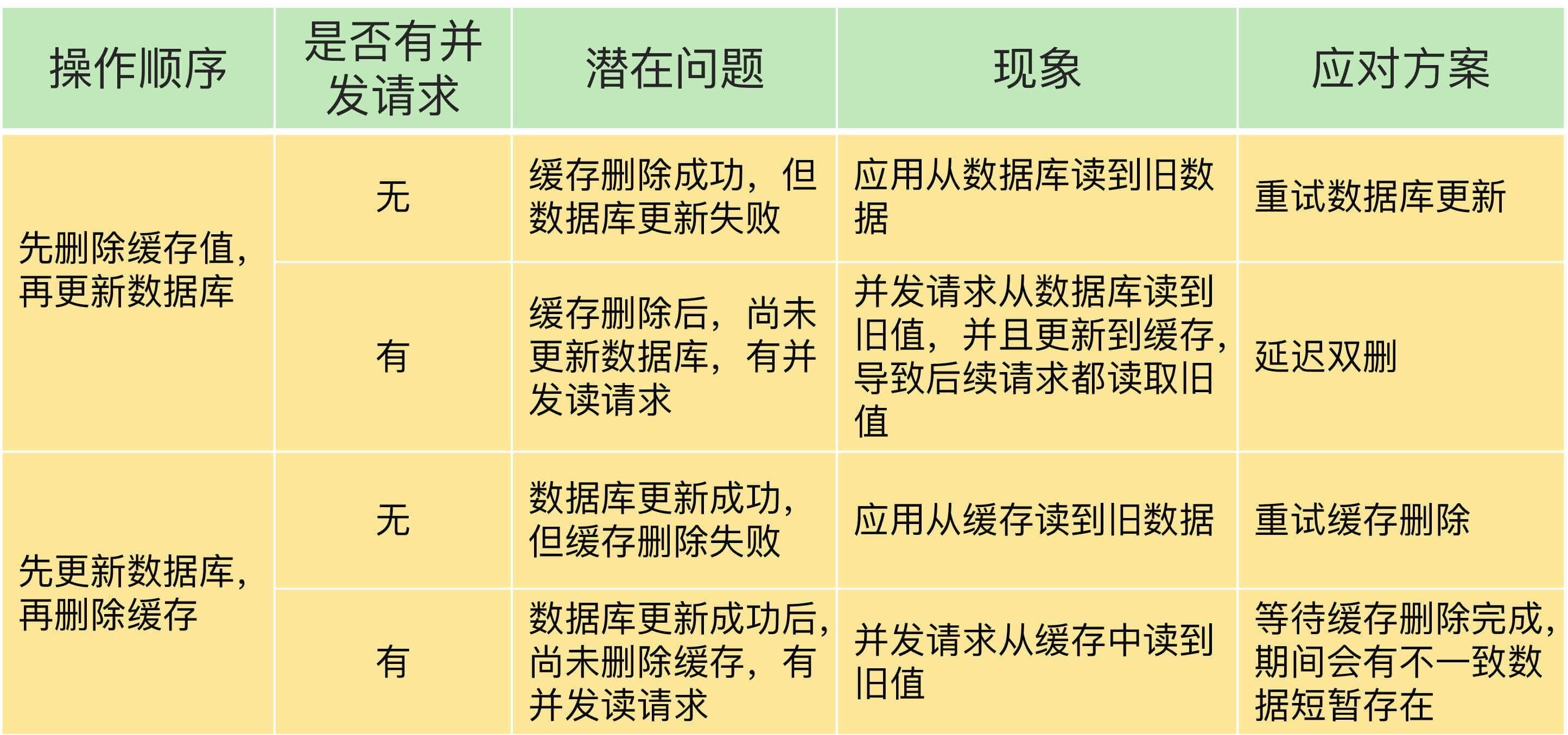
缓存或数据库只有一个操作失败
- 先删数据库数据 再删除缓存数据
- 先删除缓存数据 再删除数据库数据
- 多线程(先删缓存,再删数据库) 线程a先删除缓存数据,此时线程b查询数据库,并把旧数据放入缓存,a线程再插入数据库,之后的线程可能只会读到缓存上的旧数据
- 多线程(先删除数据库,再删除缓存)a线程删除完数据库旧数据到删除缓存这段时间,如果有读操作,那么会读到旧数据,等到a线程更新完缓存,缓存就为新的数据。
# 数据不一致的解决方案
- 重试机制
- 针对第三点 可以让a线程sleep 一小段时间 目的是为了 让像b线程这些查询操作 完成将旧数据放入缓存的操作,之后a线程再更新下缓存,sleep时间需要实测,比较难界定。
# 缓存雪崩、缓存击穿和缓存穿透 是什么?
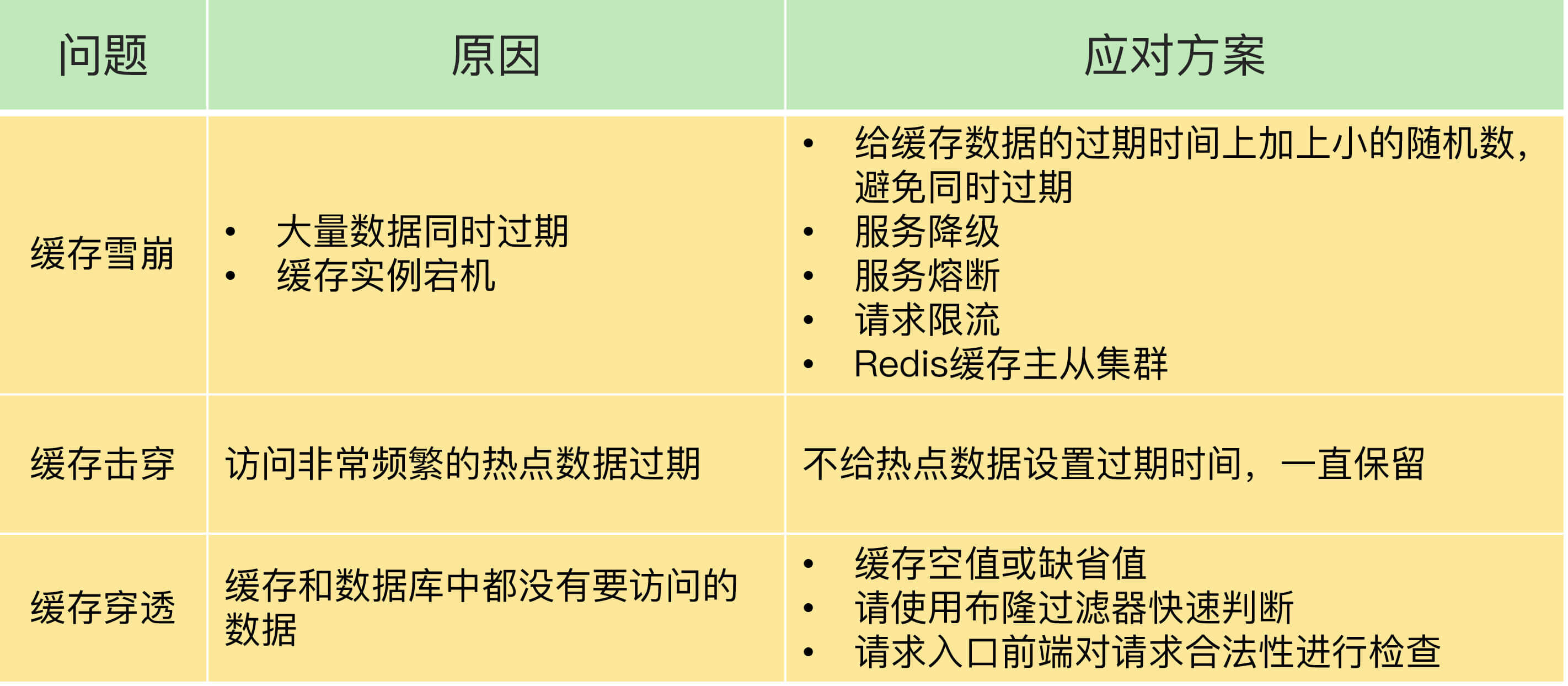
# 缓存雪崩
大量缓存同时失效的情况,大量请求一下子打在数据库上。
场景:1.当大量缓存设置的相同过期时间。2. redis服务器宕机,缓存不可用
解决方案:
- 缓存设置不同的过期时间。
- 服务熔断或请求限流机制,非核心数据请求过多,返回预定于错误。
- 3.采用redis集群,防止的那个服务宕机
# 缓存击穿
针对的是热点缓存数据,请求不能再热点缓存中处理,会大量涌入数据库中,会影响数据库处理其他请求。缓存击穿的情况,经常发生在热点数据过期失效时。
解决方案:
- 不设置热点数据的过期时间,这样热点数据一直都在,请求不会大量涌入数据库。
# 缓存穿透
这个和上面两种都不一样,上面都是缓存失效造成的问题,缓存击穿则是缓存和数据库数据都失效了,导致每个请求都需要完整的走一遍。给数据库造成巨大的压力。
那么,缓存穿透会发生在什么时候呢?一般来说,有两种情况。
- 业务层误操作:缓存中的数据和数据库中的数据被误删除了,所以缓存和数据库中都没有数据;
- 恶意攻击:专门访问数据库中没有的数据。
解决方案:
- 设置缺省值,如果缓存的数据为空,那么直接返回缺省值,避免大量请求涌入数据库
- 布隆过滤器,一个值为0的数组和N个函数,可以用来判断某个数据是否存在 布隆过滤器由一个长度为 m 的位数组(bit array)和 k 个独立的哈希函数组成。位数组的初始值都为 0。
- 在请求入口的前端进行请求检测。
1.服务降级:不管在什么情况下,服务降级的流程都是先调用正常的方法,再调用fallback的方法。 也就是服务器繁忙,请稍后再试,不让客户端等待并立刻返回一个友好提示。
2.服务熔断:假设服务宕机或者在单位时间内调用服务失败的次数过多,即服务降级的次数太多,那么则服务熔断。 并且熔断以后会跳过正常的方法,会直接调用fallback方法,即所谓“服务熔断后不可用”。 类似于家里常见的保险丝,当达到最大服务访问后,会直接拒绝访问,拉闸限电,然后调用服务降级的fallback方法,返回友好提示。
3.限流,是指在使用缓存和降级无效的场景。比如当达到阈值后限制接口调用频率,访问次数,库存个数等,在出现服务不可用之前,提前把服务降级。只服务好一部分用户。
上次更新: 2023/06/14, 22:08:07