 InnoDB记录结构
InnoDB记录结构
# InnoDB记录结构
# innoDB存储引擎介绍
存储引擎的作用就是内存和磁盘打交道,负责将数据在他两之间传输,为了提高传输效率,提出了“页”的概念,也就是在一般情况下,为了减少io次数,一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。
页:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16 KB。
# innoDB行格式
行格式:记录在磁盘上的存放方式称为行格式。
四种行格式:Compact 、 Redundant 、Dynamic 和 Compressed 行格式。
# 指定行格式命令
REATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称
ALTER TABLE 表名 ROW_FORMAT=行格式名称
mysql> CREATE TABLE record_format_demo (
-> c1 VARCHAR(10),
-> c2 VARCHAR(10) NOT NULL,
-> c3 CHAR(10),
-> c4 VARCHAR(10)
-> ) CHARSET=ascii ROW_FORMAT=COMPACT;
Query OK, 0 rows affected (0.03 sec)
2
3
4
5
6
7
8
9
10
11
# 介绍InnoDB的Compact行格式
可以把记录分为记录额外信息,记录真实数据
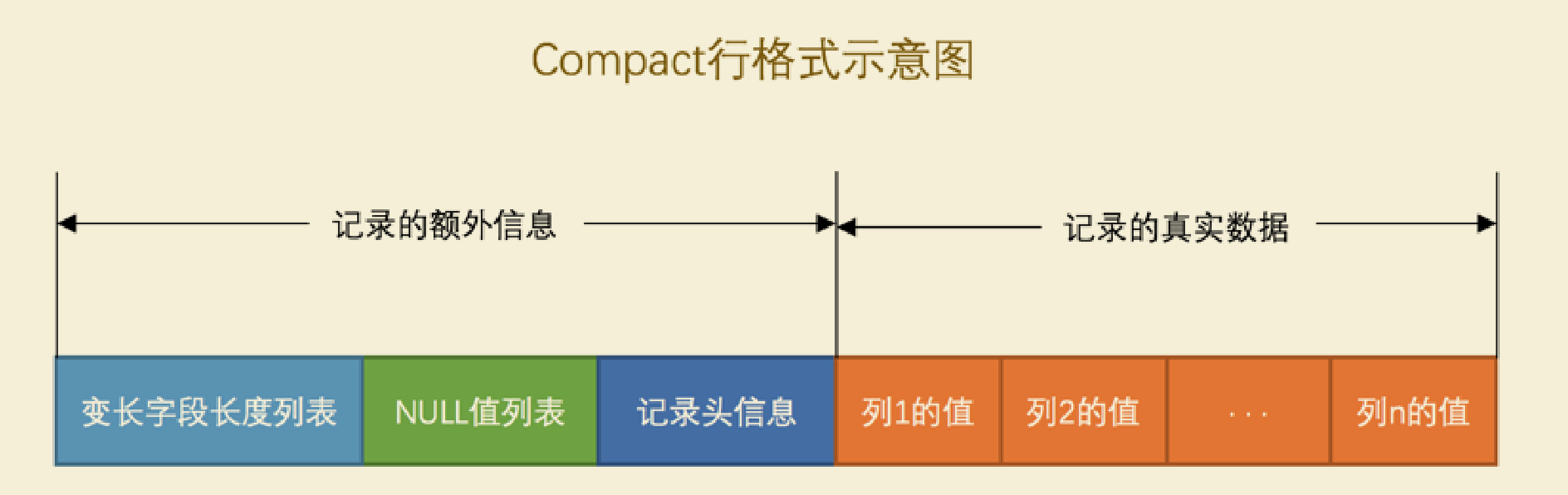
# 记录额外信息
边长字段长度列表:记录可变长度字段的真实数据占用的字节数
注意:变长字段长度列表中只存储值为 非NULL 的列内容占用的长度,值为 NULL 的列的长度是不储存的
null值列表:值为 NULL 的列统一管理起来,存储到 NULL 值列表中
记录头信息:固定的 5 个字节组成,存放记录的描述信息
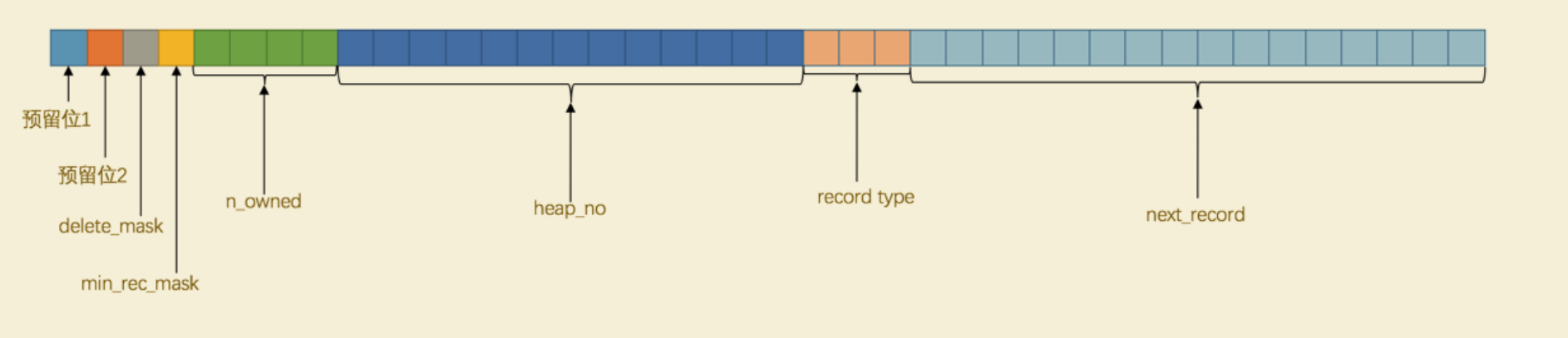

# 真实数据
除了存放真实数据外,还会添加隐藏列,具体如下:
| 列名 | 是否必须 | 占用空间 | 描述 |
|---|---|---|---|
| row_id | 否 | 6 字节 | 行ID,唯一标识一条记录 |
| transaction_id | 是 | 6 字节 | 事务ID |
| roll_pointer | 是 | 7 字节 | 回滚指针 |
注意:实际上这几个列的真正名称其实是:DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR,我们为了美观才写成了row_id、transaction_id和roll_pointer。
# char(M)的存储格式
对于 CHAR(M) 类型的列来说,当列采用的是定长字符集时,该列占用的字节数不会被加到变长字段长度列表,而如果采用变长字符集时,该列占用的字节数也会被加到变长字段长度列表
# 表的行格式采用compact实验
create table record_test_1 (
id bigint,
score double,
name char(4),
content varchar(8),
extra varchar(16)
)row_format=compact;
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (1, 78.5, 'hash', 'wodetian', 'nidetiantadetian');
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (65536, 17983.9812, 'zhx', 'shin', 'nosuke');
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (NULL, -669.996, 'aa', NULL, NULL);
INSERT INTO `record_test_1`(`id`, `score`, `name`, `content`, `extra`) VALUES (2048, NULL, NULL, 'c', 'jun');
2
3
4
5
6
7
8
9
10
11
12
目前表结构
+-------+------------+------+----------+------------------+
| id | score | name | content | extra |
+-------+------------+------+----------+------------------+
| 1 | 78.5 | hash | wodetian | nidetiantadetian |
| 65536 | 17983.9812 | zhx | shin | nosuke |
| NULL | -669.996 | aa | NULL | NULL |
| 2048 | NULL | NULL | c | jun |
+-------+------------+------+----------+------------------+
2
3
4
5
6
7
8
windows下 到C:\ProgramData\MySQL\MySQL Server 5.7\Data\test下找到文件record_test_1.ibd,使用notepad++ 16进制打开(在notepad++找到插件->HEX-editor-> view in HEX,如果没有就安装一个)
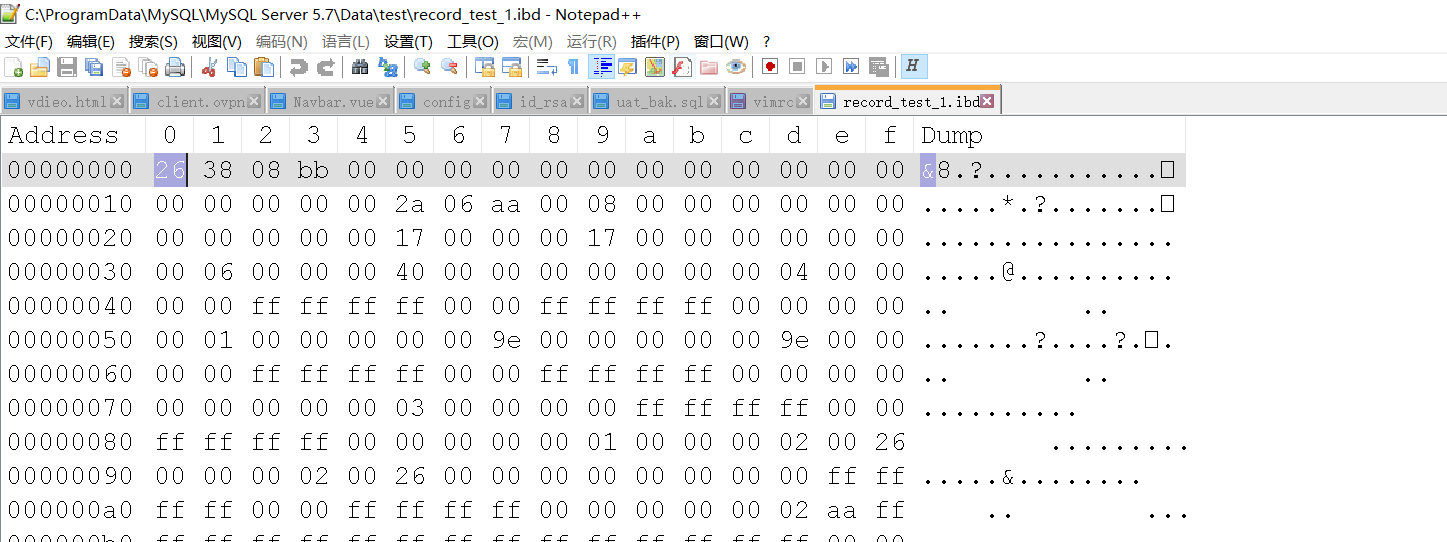
我们先来看第一条记录的content,extra字段,字段长度分别为8和16,字符类型都是可变的,所以这两个字段是会被存放在变长字段长度列表,
又因为存放时的顺序是逆序的,所以应该是 10 08(这里用的是16进制)

# Redundant行格式
没太理解,暂不记录
# 行溢出数据
# VARCHAR(M)最多能存储的数据
存储一个 VARCHAR(M) 类型的列,其实需要占用3部分存储空间:
- 真实数据
- 真实数据占用字节的长度
- NULL 值标识,如果该列有 NOT NULL 属性则可以没有这部分存储空间
首先前提是VARCHAR(M) 类型的列最多可以占用 65535 个字节!
现在假设列的字符集是ascii 字符集(一个字符代表一个字节),表只有一个列
- 如果列有
not null则不需要花一个字节空间存null值,真实数据的长度可能占用2个字节,即可以最大有65533个字节来存储真实数据,则可以存65533个字符 - 如果列没有
not null则需要花一个字节空间存null值,且真实数据的长度可能占用2个字节,即可以最大有65532个字节来存储真实数据,则可以存65532个字符
但是,如果字符集不是ascii 字符集呢?是utf8呢?gbk呢?
其实前面算的最大字节数是不用变得,因为字符集的改变,一个字符最大占用字节数量变了。
比如字符集是utf8的话,一个字符最大使用3个字节,所以上面的②情况,最大存储字符数65532/3=21844
上述所言在列的值允许为NULL的情况下,gbk字符集下M的最大取值就是32766,utf8字符集下M的最大取值就是21844,这都是在表中只有一个字段的情况下说的,一定要记住一个行中的所有列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过65535个字节!
# 记录中的数据太多产生的溢出
在 Compact 和 Reduntant 行格式中,对于占用存储空间非常大的列,在 记录的真实数据 处只会存储该列的一部分数据,把剩余的数据分散存储在几个其他的页中,然后 记录的真实数据 处用20个字节存储指向这些页的地址(当然这20个字节中还包括这些分散在其他页面中的数据的占用的字节数),从而可以找到剩余数据所在的页, 如图所示:
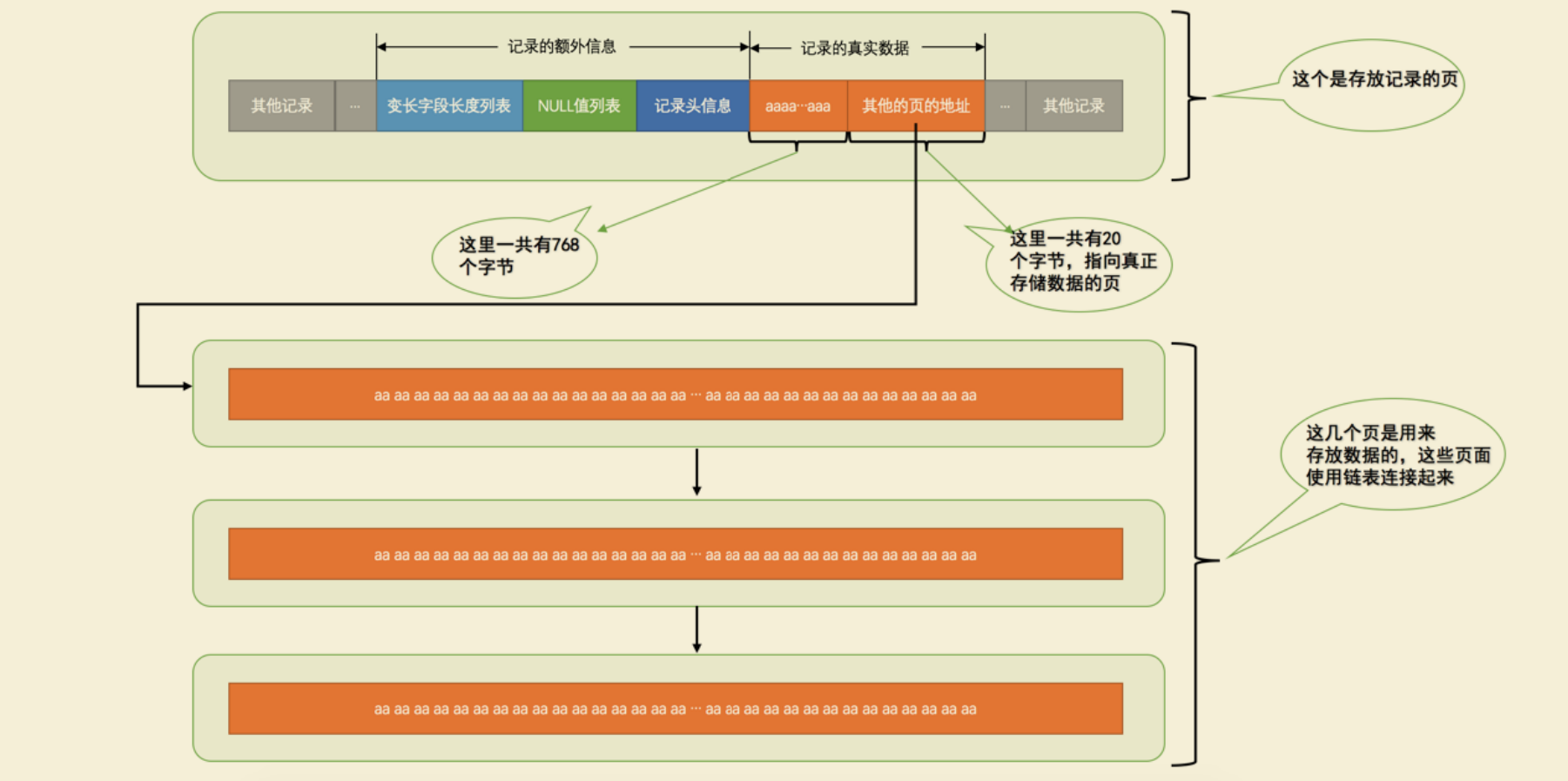
最后需要注意的是,不只是 VARCHAR(M) 类型的列,其他的 TEXT、BLOB 类型的列在存储数据非常多的时候也会发生 行溢出
# 行溢出的临界点
假设一个列中存储的数据字节数为n,那么发生 行溢出 现象时需要满足这个式子:
136 + 2×(27 + n) > 16384
n > 8098
解释:136byte一页的额外信息+一行记录(27byte的记录额外信息+nbyte真实数据)*2 > 16384byte一页最大存储字节数
2
3
注释:
136:每个页除了存放我们的记录以外,也需要存储一些额外的信息,乱七八糟的额外信息加起来需要 136 个字节的空间(现在只要知道这个数字就好了),其他的空间都可以被用来存储记录。
2:一个页中至少存放两行记录。
27:每个记录需要的额外信息是 27 字节。
16384: 一页16kb = 16384byte
但这只是假设一个表只有一个列的情况,有多个列的话计算公式和结果都要修改
结论:你不用关注这个临界点是什么,只要知道如果我们想一个行中存储了很大的数据时,可能发生 行溢出 的现象。
# Dynamic和Compressed行格式
# Dynamic格式
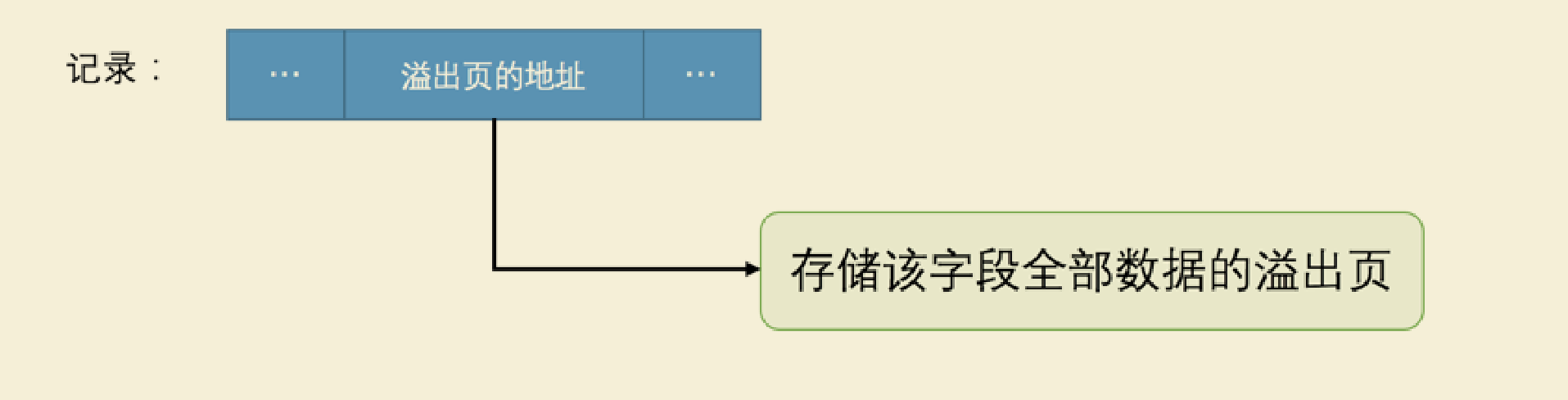
MySQL 版本是 5.7 ,它的默认行格式就是 Dynamic ,这俩行格式和 Compact 行格式挺像,只不过在处理 行溢出 数据时有点儿分歧,它们不会在记 录的真实数据处存储字段真实数据的前 768 个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址,就像这样:
# Compressed行格式
Compressed 行格式和 Dynamic 不同的一点是, Compressed 行格式会采用压缩算法对页面进行压缩,以节省空间。