 redis淘汰策略机制
redis淘汰策略机制
# redis 淘汰策略
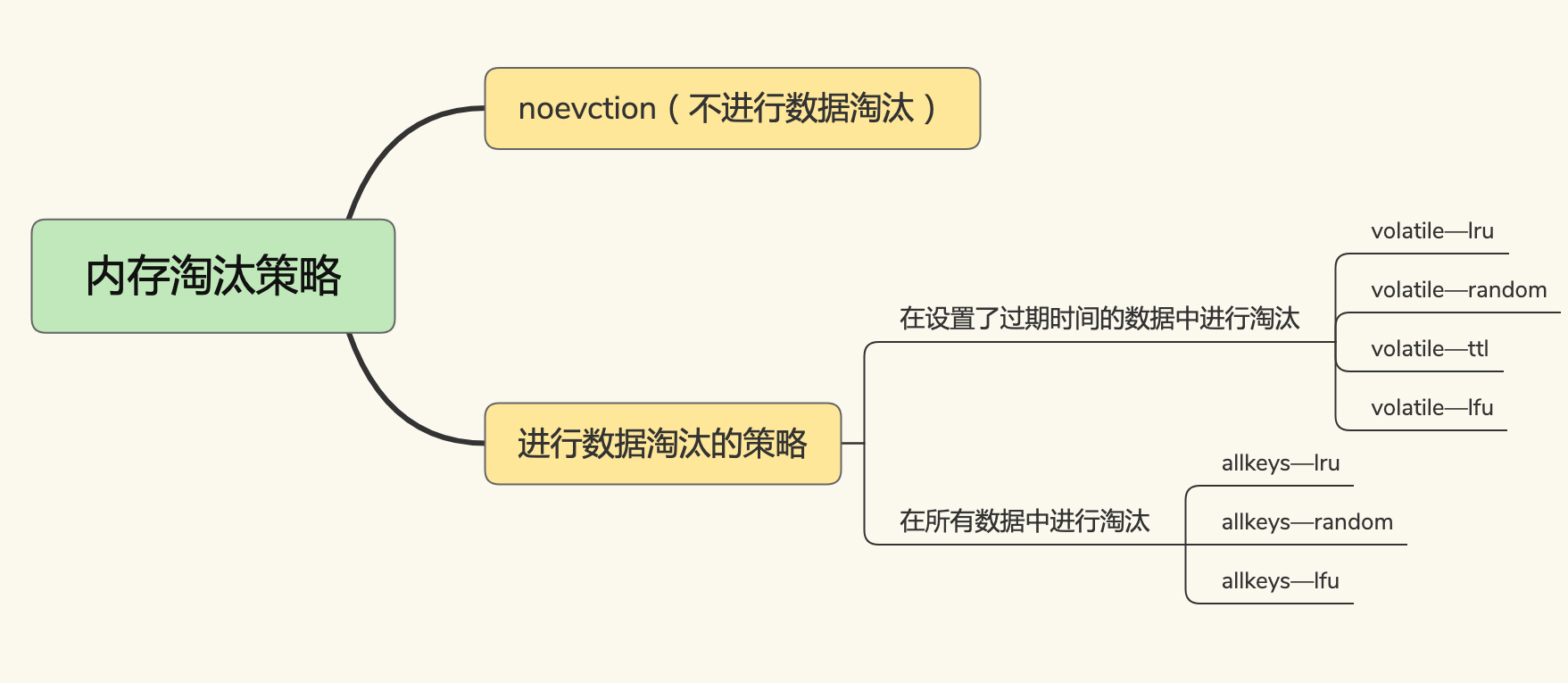
分类角度:会进行淘汰的和不进行淘汰的
不会进行淘汰的 noeviction
会进行淘汰的
- 过期内淘汰的 volatile-random、volatile-ttl、volatile-lru、volatile-lfu
- 全部数据淘汰的 allkeys-lru、allkeys-random、allkeys-lfu
# lru策略解释
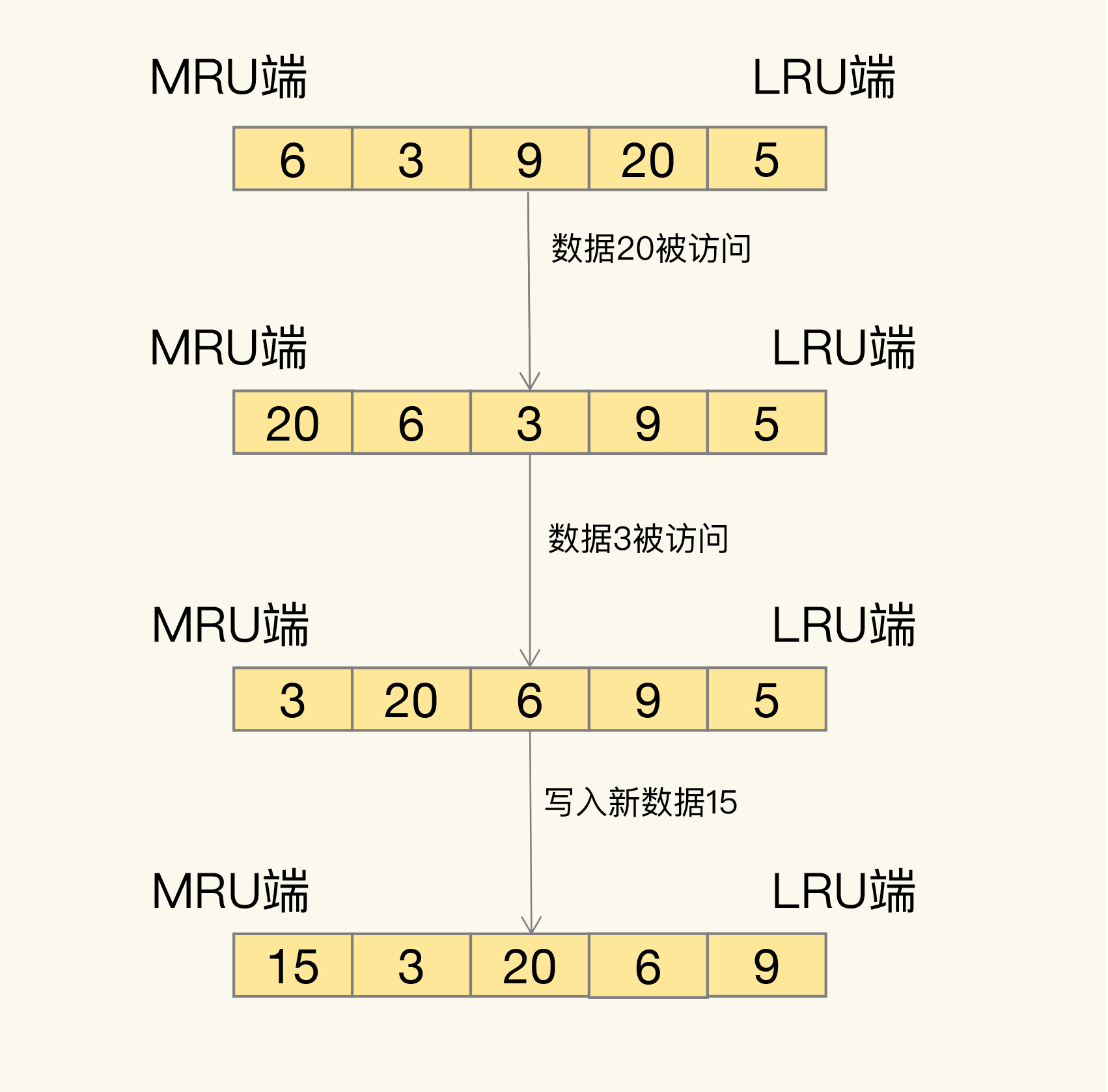
least recent used 最近最少使用
将所有数据使用链表保存,链表的头和尾分别表示 MRU 端和 LRU 端,分别代表最近最常使用的数据和最近最不常用的数据。
当其中的数据被访问时,数据会被加在表头上,随之改变的是 被访问数据的原位置到表头之间的数据,位置都需要往后挪一位,这样就链表的尾部,是最近最少使用的数据。
# redis 的lru策略:
最大的不同是,不将所有数据保存在一个链表中,而是创建自定义长度的集合,第一次获取数据是从所有数据中随机获取一定数量的元素存入集合(如果淘汰机制是volatile类型的,那么从过期内的数据中获取),Redis 默认会记录每个数据的最近一次访问的时间戳(由键值对数据结构 RedisObject 中的 lru 字段记录),根据lru字段选取最小的lru值,并将此数据淘汰掉,之后集合会不断补充新的数据,前提是 补充进来的数据 ,它的lru值需要比集合中元素lru最小的还小。
Redis 提供了一个配置参数 maxmemory-samples,这个参数就是 Redis 选出的数据个数 N。例如,我们执行如下命令,可以让 Redis 选出 100 个数据作为候选数据集:
CONFIG SET maxmemory-samples 100
# redis 的lfu策略
redis的lru 已经能淘汰大多过期数据了,但是扫描式单次查询情况,会造成缓存污染。解释一下,按照lru策略,如果第一次查询到热点数据【6】,热点数据【6】会记录对应的lru值,然后发生了一次全表扫描,把大量的数据都放到了缓存里,以至于集合的内容都被替换成刚刚全表查询的数据,那么热点数据【6】会被淘汰,然而像这种扫描式单次查询,往往发生的很少,不属于热点数据,但是却把热点数据淘汰了,这种只有之后再把热点数据放入缓存了。
基于上面的情况redis的lfu策略把lru改良了下,具体是:
- redisObject上的lru字段被分为16字节用来存访问时间,8字节用来存访问次数
- 第一次随机取N个数据放入固定长度集合,先比较每个对象的次数,最少的淘汰,如果访问次数相同,那么比较最近访问时间,最小的淘汰。
# InnoDB缓冲池的lru策略:
InnoDB设计lru策略感觉又更加高明!他主要是为了解决 全表扫描造成缓存数据被替换的问题。
因为缓存一般都是使用内存作为存储介质,比磁盘昂贵的多,所以缓存不可能无限大,只能在有限的空间里面自由发挥。mysql的缓冲池中也会维持一个lru链表,用来淘汰不常用的数据,链表又会分为yang数据区和old数据区,(是不是有点jvm老年代和新生代的熟悉感,哈哈)yang数据区和old数据区占比一般是3/7,占比可以自己调节。
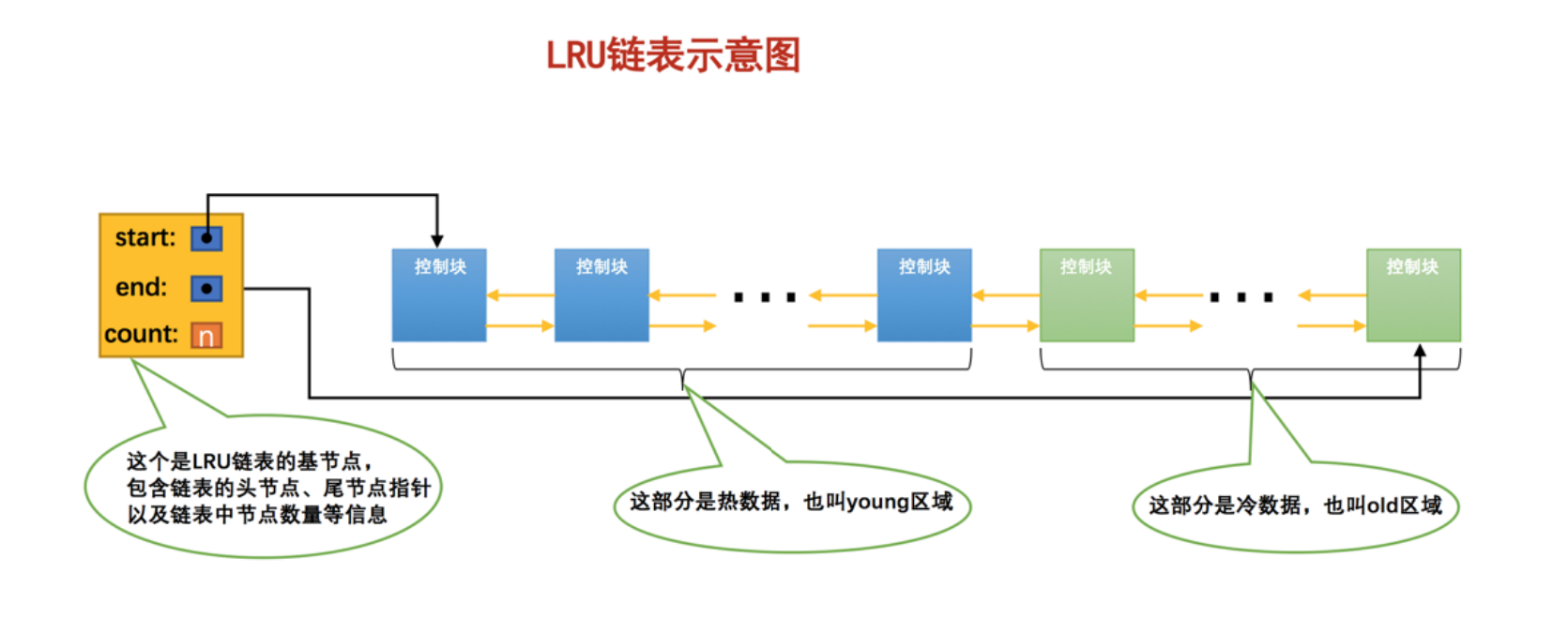
- 首先会有一个预读的过程,将可能会查到的数据存入缓冲池内,首次存入lru链表的数据,会存放在old区域的表头,这样链表上就有数据啦
- 随着读请求过来,最近读到的数据会被放在old区域的表头,然后old区域多出来的数据会被淘汰。
- 如果被存放在old区域的数据在指定范围时间内再次被读取,那么这条数据会被晋升到yang区域,这样做的目的就是为了解决全表扫描,一次性将数据挤满了lru链表,从而“错误"淘汰了热点数据。