 redo日志(下)
redo日志(下)
# redo log的刷盘时机
- log buffer 空间不足时(大概一半左右)
- 事务提交时
- 后台线程不停的刷刷刷(大概每秒刷一次)
- 正常关闭服务器时
- 做所谓的 checkpoint
# redo日志文件组
磁盘上的 redo 日志文件不只一个,而是以一个 日志文件组 的形式出现的
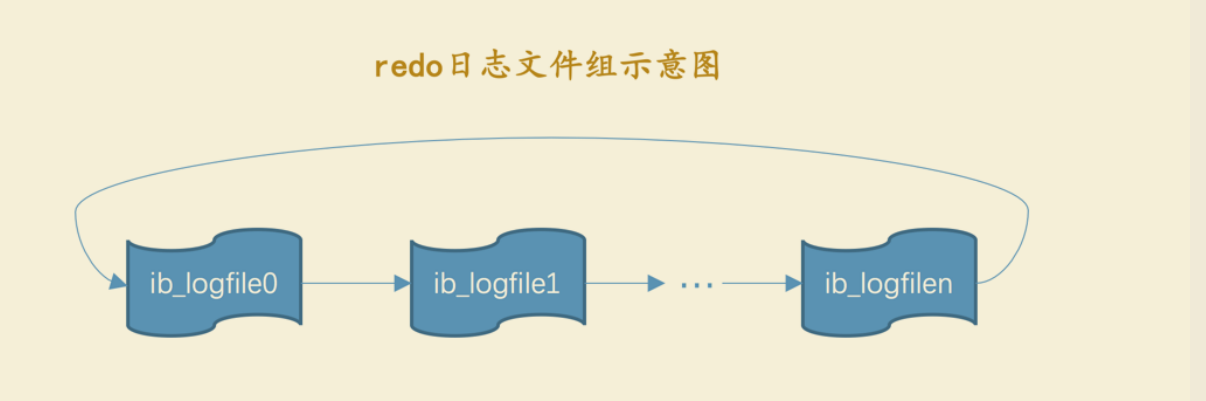
MySQL 的数据目录(使用 SHOW VARIABLES LIKE 'datadir' 查看)下默认有两个名为 ib_logfile0 和ib_logfile1的文件, log buffer中的日志默认情况下就是刷新到这两个磁盘文件中。如果我们对默认的redo 日志文件不满意,可以通过下边几个启动参数来调节:
innodb_log_group_home_dir
该参数指定了 redo 日志文件所在的目录,默认值就是当前的数据目录。
innodb_log_file_size
该参数指定了每个 redo 日志文件的大小,在 MySQL 5.7.21 这个版本中的默认值为 48MB
innodb_log_files_in_group
该参数指定 redo 日志文件的个数,默认值为2,最大值为100。
总共的 redo 日志文件大小其实就是: innodb_log_file_size × innodb_log_files_in_group 。
# redo日志文件格式
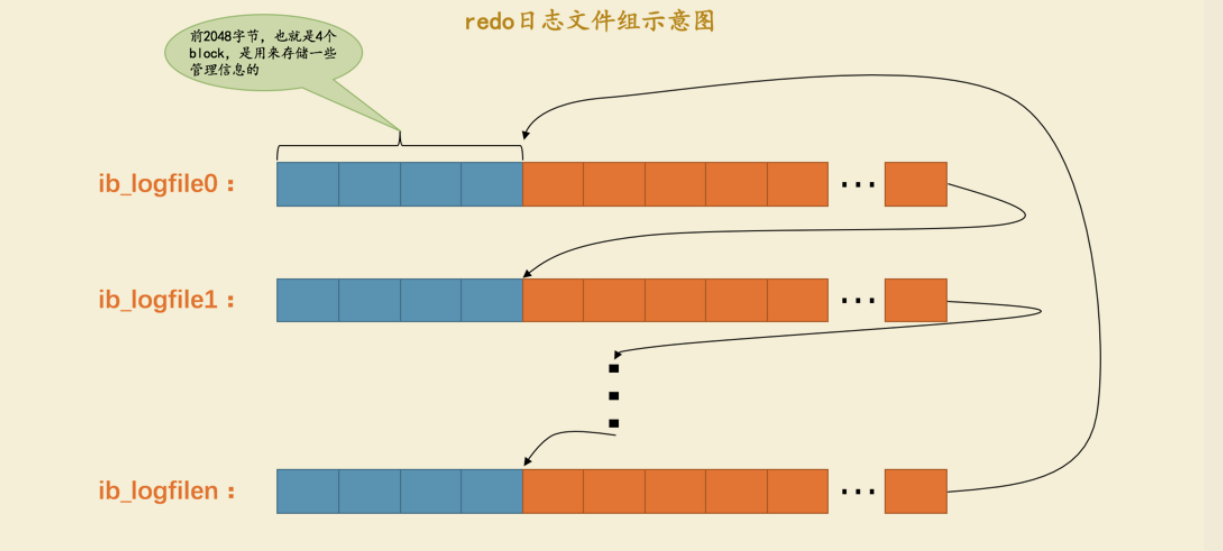
我们前边说过 log buffer 本质上是一片连续的内存空间,被划分成了若干个 512 字节大小的 block 。将logbuffer中的redo日志刷新到磁盘的本质就是把block的镜像写入日志文件中,所以 redo 日志文件其实也是由若干个 512 字节大小的block组成。redo 日志文件组中的每个文件大小都一样,格式也一样,都是由两部分组成:
- 前2048个字节,也就是前4个block是用来存储一些管理信息的。
- 从第2048字节往后是用来存储 log buffer 中的block镜像的。
所以每次一开始写都是重ib_logfile的2048字节处开始写
# redo日志缓存写入磁盘过程

图中的:
write pos 和 checkpoint 的移动都是顺时针方向; write pos ~ checkpoint 之间的部分(图中的红色部分),用来记录新的更新操作; check point ~ write pos 之间的部分(图中蓝色部分):待落盘的脏数据页记录; 如果 write pos 追上了 checkpoint,就意味着 redo log 文件满了,这时 MySQL 不能再执行新的更新操作,也就是说 MySQL 会被阻塞(因此所以针对并发量大的系统,适当设置 redo log 的文件大小非常重要),此时会停下来将 Buffer Pool 中的脏页刷新到磁盘中,然后标记 redo log 哪些记录可以被擦除,接着对旧的 redo log 记录进行擦除,等擦除完旧记录腾出了空间,checkpoint 就会往后移动(图中顺时针),然后 MySQL 恢复正常运行,继续执行新的更新操作。
所以,一次 checkpoint 的过程就是脏页刷新到磁盘中变成干净页,然后标记 redo log 哪些记录可以被覆盖的过程。