 字符集和比较规则
字符集和比较规则
# 字符集和比较规则
# 字符集简介
作用:为了让数据在人和计算机都能被”看的懂“。
我们知道在计算机中只能存储二进制数据,那该怎么存储字符串呢?当然是建立字符与二进制数据的映射关系了,建立这个关系最起码要搞清楚两件事儿:
- 你要把哪些字符映射成二进制数据? 也就是界定清楚字符范围。
- 怎么映射? 将一个字符映射成一个二进制数据的过程也叫做 编码 ,将一个二进制数据映射到一个字符的过程叫做 解码 。 人们抽象出一个 字符集 的概念来描述某个字符范围的编码规则。比方说我们来自定义一个名称为 xiaohaizi 的字符集,它包含的字符范围和编码规则如下: 包含字符 'a' 、 'b' 、 'A' 、 'B' 。 编码规则如下: 采用1个字节编码一个字符的形式,字符和字节的映射关系如下: 'a' -> 00000001 (十六进制:0x01) 'b' -> 00000010 (十六进制:0x02) 'A' -> 00000011 (十六进制:0x03) 'B' -> 00000100 (十六进制:0x04) 有了 xiaohaizi 字符集,我们就可以用二进制形式表示一些字符串了,下边是一些字符串用 xiaohaizi 字符集编码后的二进制表示: 'bA' -> 0000001000000011 (十六进制:0x0203) 'baB' -> 000000100000000100000100 (十六进制:0x020104) 'cd' -> 无法表示,字符集xiaohaizi不包含字符'c'和'd'
—— 引用《MySQL是怎么运行的》
# 比较规则简介
- 因为在mysql对英文大小写是不敏感的,所以比较时,会将两个大小写不同的字符全都转为大写或者小写。
- 再比较这两个字符对应的二进制数据。
注意:同一种字符集可以有多种比较规则
# MySQL中的utf8和utf8mb4
utf8mb3 :阉割过的 utf8 字符集,只使用1~3个字节表示字符。
utf8mb4 :正宗的 utf8 字符集,使用1~4个字节表示字符。
mysql字符集的查看
SHOW (CHARACTER SET|CHARSET) [LIKE 匹配的模式];
1
mysql比较规则的查看
SHOW COLLATION [LIKE 匹配的模式];
1
注意:每种字符集对应若干种比较规则,每种字符集都有一种默认的比较规则
# mysql有四个级别的字符集和比较规则
- 服务器级别
- 数据库级别
- 表级别
- 列级别
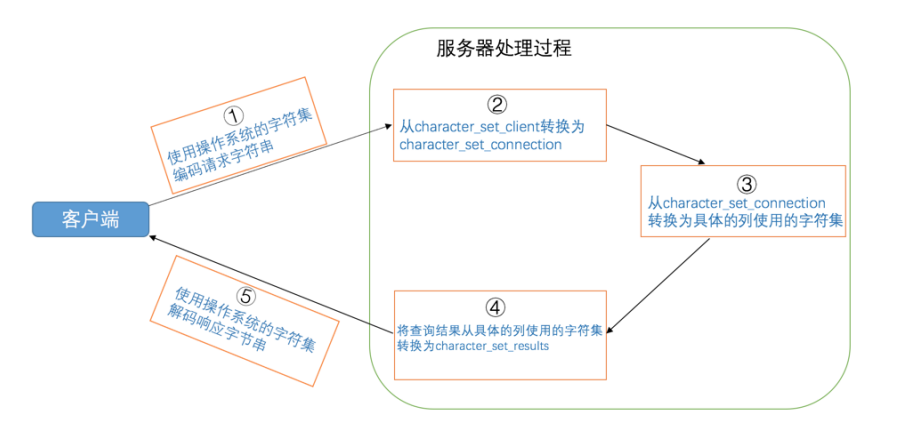 如果对于同一个字符串编码和解码使用的字符集不一样,会产生意想不到的结果
如果对于同一个字符串编码和解码使用的字符集不一样,会产生意想不到的结果
我们知道字符 '我' 在 utf8 字符集编码下的字节串长这样: 0xE68891 ,如果一个程序把这个字节串发送到另一个程序里,另一个程序用不同的字符集去解码这个字节串,假设使用的是 gbk 字符集来解释这串字节,解码过程 就是这样的:
- 首先看第一个字节 0xE6 ,它的值大于 0x7F (十进制:127),说明是两字节编码,继续读一字节后是 0xE688 ,然后从 gbk 编码表中查找字节为 0xE688 对应的字符,发现是字符 '鎴'
- 继续读一个字节 0x91 ,它的值也大于 0x7F ,再往后读一个字节发现木有了,所以这是半个字符。
- 所以 0xE68891 被 gbk 字符集解释成一个字符 '鎴' 和半个字符。 假设用 iso-8859-1 ,也就是 latin1 字符集去解释这串字节,解码过程如下:
- 先读第一个字节 0xE6 ,它对应的 latin1 字符为 æ 。
- 再读第二个字节 0x88 ,它对应的 latin1 字符为 ˆ 。
- 再读第二个字节 0x91 ,它对应的 latin1 字符为 ‘ 。
- 所以整串字节 0xE68891 被 latin1 字符集解释后的字符串就是 '我' 可见,如果对于同一个字符串编码和解码使用的字符集不一样,会产生意想不到的结果,作为人类的我们看上去就像是产生了乱码一样。
# varchar和char在MySQL层的区别
根据MySQL的官方文档The CHAR and VARCHAR Types中的描述, varchar和char的区别主要有:
最大长度:char是255,varchar是65535,单位是字符(而不是字节)。 尾随空格:char会将尾随空格去掉,而varchar不会。 因为存储时,char会用空格填充至指定长度,所以取出时需要去除空格。如果char字段有唯一索引,a和a 会提示唯一索引冲突。 存储空间占用:varchar会占用额外的1~2字节来存储字符串长度。如果最大长度超过255,就需要2字节,否则1字节。
上次更新: 2023/08/14, 08:01:22