 io模型
io模型
# 单线程模型
 accept函数如果没有事件,则会阻塞,影响其他请求
。。。。。
accept函数如果没有事件,则会阻塞,影响其他请求
。。。。。
# 多进程模型
。。。。。
套接字 用网络地址和端口来唯一标识一个实体。那么,用来唯一标识通信两端的数据结构就叫做套接字
套接字分为连接套接字和监听套接字 连接套接字:用来接受客户端的消息事件,多个客户端的话,会产生多个 监听套接字:用来接受客户端的连接事件,服务端只会有一个
# 什么是io多路复用模型
当时redis的事件模型时,看的一知半解,始终不了解io多路复用模型,感觉想要彻底吃透redis,还是得要了解io多路复用模型。我于是重新看了io多路复用知识点,并总结下来
先了解下什么io多路复用模型,一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
我们熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
补充 文件描述符fd:是操作系统中用于访问文件、管道、套接字和其他I/O资源的抽象标识符。 简单来说调用了操作文件的函数,返回的标识符,比如下面的代码,创建一个socket,返回fd,在linux中本质就是文件,liunx可以根据fd找到socket在内存中位置。
int s = socket(AF_INET, SOCK_STREAM, 0);
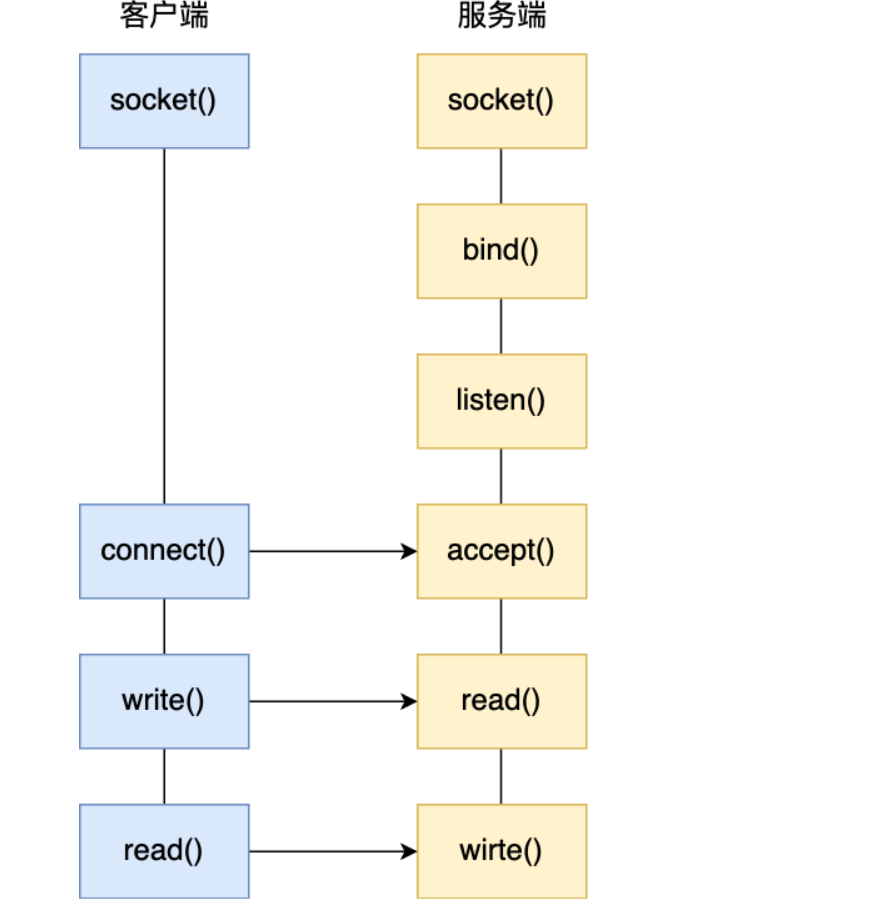
# 三个函数
正常客户端和服务端通信,服务端会创建socket,绑定端口,并且监听有没有客户端请求,三个函数前面都差不多相同,后面的步骤不大一样。
# select
socket的fd会存在bitMap数据结构中(类似0101011....),长度是1024,在一个while循环中
会将所有待检测fd的数据,从用户空间复制到内核空间,内核空间再遍历这些fd集合,检查是否有事件发生,没有则一直阻塞,如果有则置位该fd,然后将所有的fd集合返回到用户空间,注意并不是只将置位好的fd集合返回,而是返回全部,所以还需要在用户空间遍历一次,检查哪个fd是否有事件,进而处理对应逻辑。
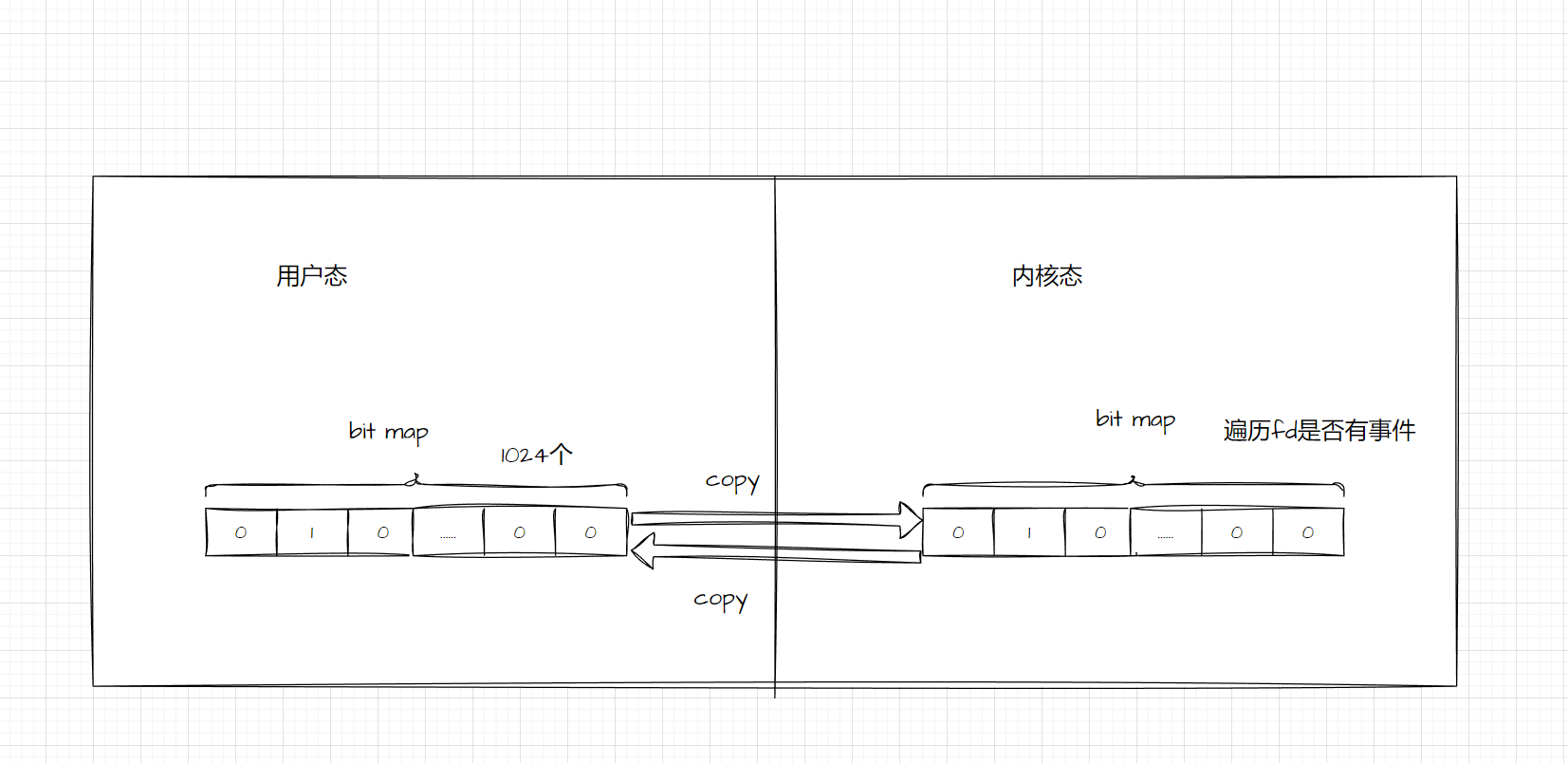
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,时间复杂度为O(n)一次是在内核态里,一个次是在用户态里 ,而且还会发生2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。下面是linux 执行select具体代码
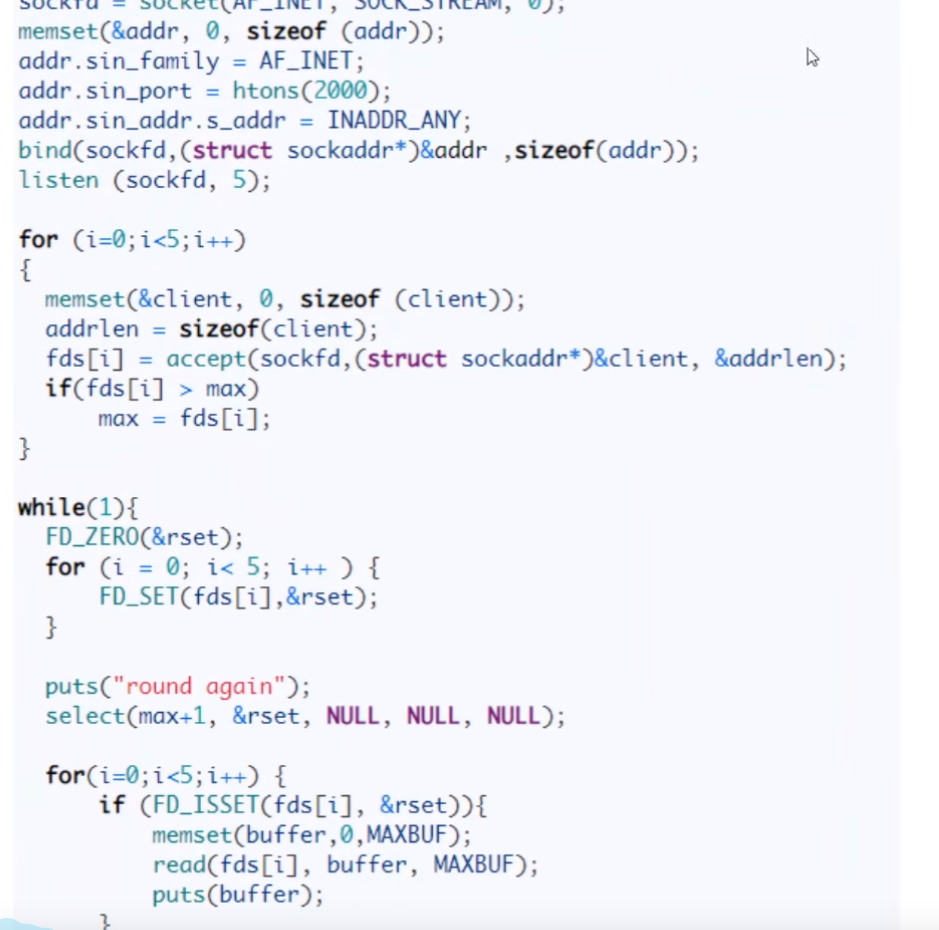
select函数解释
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
它的参数含义如下:
- nfds:文件描述符集合中所有文件描述符的范围,即最大文件描述符加 1;
- readfds:指向 fd_set 结构体的指针,包含待检测读事件的文件描述符集合;
- writefds:指向 fd_set 结构体的指针,包含待检测写事件的文件描述符集合;
- exceptfds:指向 fd_set 结构体的指针,包含待检测异常事件的文件描述符集合;
- timeout:select 函数的超时时间,指定阻塞的最长时间,可以为 NULL。
- fd_set 是一个位向量类型,表示一组文件描述符,可以使用 FD_ZERO、FD_SET、FD_CLR 和 FD_ISSET 宏操作它们。 select 函数会在 readfds、writefds 和 exceptfds 中设置的文件描述符集合中,选择其中有事件发生的文件描述符,返回这些文件描述符的个数,如果出现错误,则返回 -1。在超时时间到达之前,如果没有任何事件发生,则 select 函数将阻塞当前线程。
# poll
对select 做了一些优化,首先长度不会因为数据结构受到限制,采用了链表结构,提高了fd的个数,但是还是会 需要进行 2 次「遍历」文件描述符集合,发生2 次「拷贝」文件描述符集合
# epoll
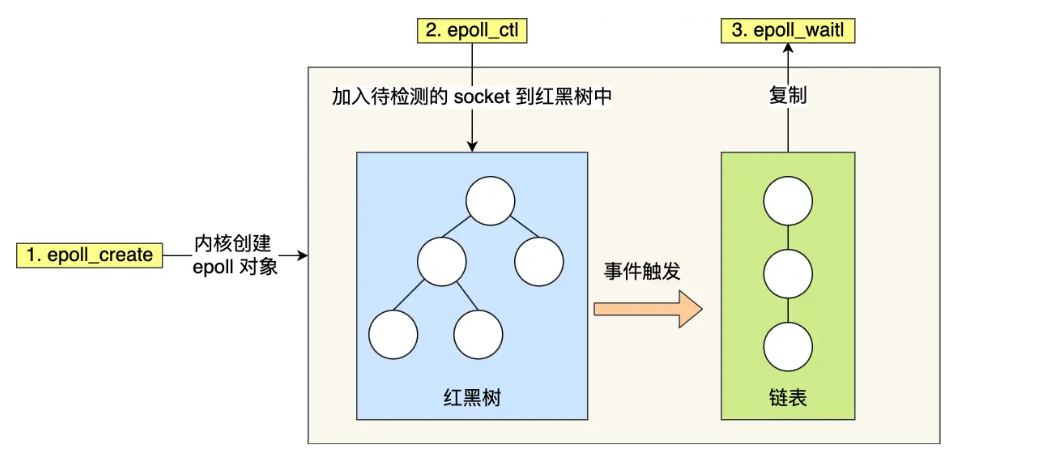
如下的代码中,先用e poll_create 创建一个 epol l对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到epfd中,最后调用 epoll_wait 等待数据。
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...);
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1) {
int n = epoll_wait(...);
for(接收到数据的socket){
//处理
}
}
2
3
4
5
6
7
8
9
10
11
12
13
在 Linux 中的 epoll 函数中,内核维护了一个红黑树和一个双向链表用于保存待检测的 socket。红黑树用于快速查找指定的文件描述符,而双向链表则用于存储已就绪的文件描述符。在 epoll 中,内核不仅保存了待检测的 socket,还保存了它们的状态信息。
这里解决来几个问题
- 使用红黑树,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)
- epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
- 内核保存了待检测的fd,不需要像select/poll,每次复制全量的fd到内核态,只需要复制需要检测的fd即可
# 了解io多路复用想到的问题
# 阻塞io如何设置为非阻塞io
- 将阻塞 I/O 变为非阻塞 I/O 的关键在于设置文件描述符的状态标志位 O_NONBLOCK。这个标志位可以通过调用 fcntl 函数来设置,它告诉操作系统在进行 I/O 操作时不要阻塞当前线程,而是直接返回错误码,表示 I/O 操作无法立即完成。
- 设置文件描述符为非阻塞 I/O 后,我们可以使用 read 和 write 等系统调用来读写数据,这些调用会立即返回,而不是像阻塞 I/O 一样一直等待数据的到来或者数据的发送完成。在非阻塞 I/O 的情况下,如果数据没有准备好,read 和 write 等调用将返回 EAGAIN 或者 EWOULDBLOCK 错误码,表示当前操作无法立即完成,需要等待更多数据的到来或者更多的发送缓冲区空间。
- 为了利用非阻塞 I/O,通常需要使用循环调用 read 和 write 等系统调用,不断检查是否有新的数据可读或者缓冲区是否已满,从而实现异步读写。另外,使用 select 或者 epoll 等多路复用函数也可以实现非阻塞 I/O。
# 非阻塞io的好处是什么 如果仅仅是立即返回,在循环中使用,我感觉效果不大呀
- 非阻塞 I/O 的好处在于它可以让程序在进行 I/O 操作的同时处理其他任务,从而提高系统的吞吐量和响应性能。相对于阻塞 I/O,非阻塞 I/O 更适合于并发编程,因为它可以充分利用 CPU 时间,避免线程被长时间阻塞,从而提高程序的并发性能。
- 在使用非阻塞 I/O 时,由于系统调用不会阻塞线程,程序可以轮询文件描述符,检查是否有数据可读或者缓冲区是否已满,从而实现异步读写。相比阻塞 I/O,非阻塞 I/O 的另一个好处是能够更好地控制 I/O 操作的流量和速度,避免出现数据积压或者阻塞的情况。
- 在实际应用中,为了进一步提高非阻塞 I/O 的效率,通常会采用多路复用函数(如 select、poll、epoll)来同时监听多个文件描述符的状态,从而实现并发 I/O,提高程序的性能和吞吐量。此外,在非阻塞 I/O 的应用中,还可以采用事件驱动的编程模型,将 I/O 操作和其他任务一起组合成一个事件处理机制,从而提高程序的性能和可维护性。
参考资料
- https://www.cnblogs.com/flashsun/p/14591563.html
- https://www.xiaolincoding.com/os/8_network_system/selete_poll_epoll.html
- https://www.bilibili.com/video/BV1qJ411w7du/?spm_id_from=333.337.search-card.all.click&vd_source=da86a2897103c910b7b5cff1f2618ad9
- https://segmentfault.com/a/1190000020194471